
The organization and management of a software development team is one of the key factors to create quality software, so it’s crucial for software teams to have clear definitions and apply good practices to make the management of the team a strength more than a weakness. In this article, We’re going to explain how ArchDaily’s Development Team handle its day to day job and why We use the methodology that We use.
Handling and manage a software development team can be a daunting task due to several factors, such as:
- Team size: as team grows, the communications between members of the team becomes more difficult, making organization harder.
- Location: some teams are distributed over different locations around the world. Again, the communication becomes harder, creating problems in the team’s organization.
- Lack of a structured methodology: sometimes dev teams don’t follow a defined methodology. This creates noise in the daily job of members and obviously makes harder to track and review the progress of the team.
Teams not necessarily need to follow one of the standard software methodologies, but it can be a big mistake to not follow any methodology at all. Just make sure your team is being managed in a clear and structured way and that every member of the team is committed (and in agreement) with the used methodology.
Here at ArchDaily, We follow an agile approach and our framework of choice is Scrum. This framework gives some useful guidelines (which can be adapted to every team’s needs) and the support of online management tools for this methodology is huge. Before going into the details of our version of Scrum, let’s talk about our team’s architecture.
Team Infraestructure
The general picture is:
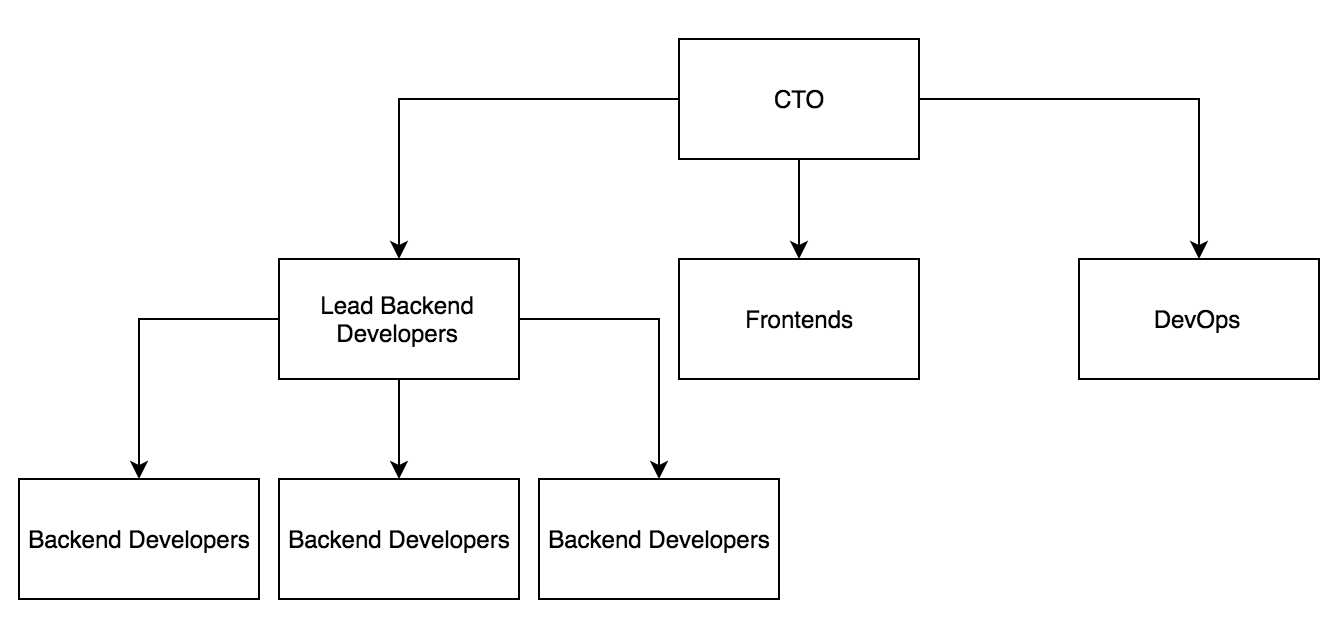
The above graph shows the general infrastructure of AD’s dev team. In general:
- CTO: is the main leader of the team. This role is in charge of defining the general work guidelines of the entire team and it’s the connection between the company strategic decisions and how the dev team transforms those decisions into real software requirements.
- Lead Backend Developers: these are the leaders of several software projects in the organization. This hierarchical representation of the team its due the high number of projects to manage and also the high number of developers in the team. This role allows to simplify the communication between stakeholders in each project and it’s a sane way for the CTO to have visibility of the entire team.
Next roles are very self-explanatory:
- Frontends
- DevOps
- Backend Developers
The main reason to decouple the standard dev role into more specific roles is to improve communication workflow inside the team. In general, every Lead Backend Developer forms a sub-team with his/her Backend Developers. The frontend and DevOps are sub-teams by themselves.
With a well defined infrastructure, the next step is to define how the chosen methodology is going to be used.
Scrum through AD’s eyes
Scrum is a well known framework for software management which became highly popular when agile software methodologies made their appearance. The workflow in Scrum is based on different stages and elements. The following ones are the key elements for our own workflow:
- Backlog Planning: In this stage, the CTO has a planning meeting with each sub-team (the second row of the team infrastructure). For example, the CTO meets a Lead Backend Developer with all the Backend Developers of their team. In this meeting, the CTO communicates to each team the work that needs to be done during the current iteration. This work is represented as high level user stories and the main objective of the meeting is to create well defined (in the sense of a developer) stories to accomplish the high level user stories. This meeting needs to be done the first day of the iteration.
- Iteration Size: we decided to use 2 week for each iteration. This timespan suits our needs the best due to the kind of requirements that We do (commonly We develop user stories big enough to span more than a week).
- Daily Meetings (or Standups): Every day, the entire team has a general short meeting in which each member of the team gives a brief overview of their work the during the past day and the work for today and also shares problems and interesting findings to the rest of the team. It must be noted that in this meeting we do not solve any problem at all. If one of the members found a blocking problem and other member has some solution, after the meeting both can have a more personal meeting to discuss in more detail their thoughts. The meeting must not exceed 15-20 minutes. This meeting allows to every member of the team to have visibility and to improve software reuse by sharing solutions to common problems between members.
- Constant Backlog Revision: During the iteration is allowed to add more stories to the backlog by any member of the team. This is useful for example if a dev thinks that one story can be splitted into two more atomic stories. We favor atomic stories in the backlog.
Summarizing:
| Stage or Activity | Main characteristics |
|---|---|
| Backlog Planning |
|
| Iterations Size | 2 weeks |
| Daily Meetings |
|
| Constant Backlog Revision | It is allowed to add/modify stories in the backlog (to favor for example atomicity) |
Implementation
The online tool that we use for our software development workflow is PivotalTracker. Basically, We have one project for every sub-team inside our main team:
- Backend Projects: one project for each backend sub-team
- Frontend Project: a project for the frontend team
- Ops Project: a project for DevOps related tasks
To have entire visibility of team’s tasks, PivotalTracker has the concept of Workspaces:
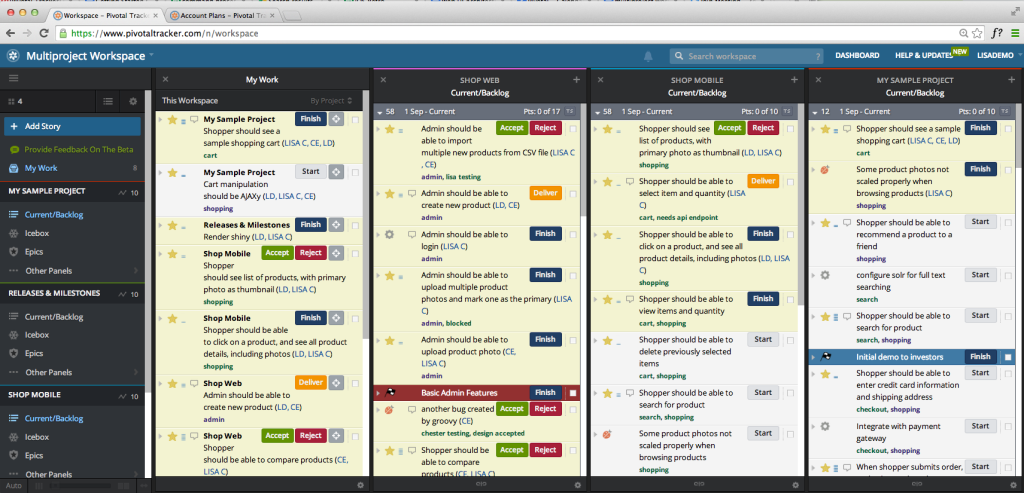
which gives the ability to have in one board, access to selected (or all) the boards on different projects.
In PivotalTracker, there are four different types of stories:
- Features: These represent the typical concept of an user story. Features deliver verifiable business value to project’s stakeholders.
- Chores: These kind of stories don’t add direct value to stakeholders (for example: “Update SSL Certs”) but they are necessary for the success of the project.
- Bugs: They are indeed bugs found in the project.
- Releases: These are merely milestones markers. They represent a point in time where a group of stories (or more general, a complete feature) needs to be done.
Backlog Planning In Practice
For the backlog planning, developers should use the Icebox board in the current working project. Every new feature should be added to the icebox as a feature/chore story (or several stories) and it should be as atomic as possible. If in the backlog planning meeting, devs note that is going to take to much time to split a general feature into atomic stories, then after the meeting (in no more than 2 days) the owner or requester of that feature should do that job.
After adding all the stories for the current iteration into the icebox, the corresponding owner together with the CTO should move every story into the backlog and estimate the points for that story (in our case, every point corresponds to 1 working hour). As a general rule, there can’t be unestimated stories in the backlog.
As the final result of this stage, the icebox should be empty and the backlog should have all estimated features (as atomic as possible) to do during the current iteration.
Organization of Cards in the Backlog Planning Stage
A general PivotalTracker card looks like:

The estimation points are only available for features and every card should have a requester and an owner. The requester should take special care to give a comprehensive description of the card and to use labels to recognize the card in relation with other cards in the same project. Labels could be anything. The only rule is that they need to be useful. Also, whatever interaction between requester and owners (or related devs) should be registered into the card’s activity for future reference.
If a feature involves more than one story, the requester (or owner) should create an Epic. In simple terms, epics are cards that group a set of other cards which represent an entire feature as a whole. For example, if in the current iteration the team needs to do a big feature which is splitted into several atomic features, then the atomic set of features compose an epic. In PivotalTracker, for every epic exists a label (with a purple color) associated with that epic. Then, for every story that belongs to the epic, the dev should add that label, PivotalTracker will do the rest:
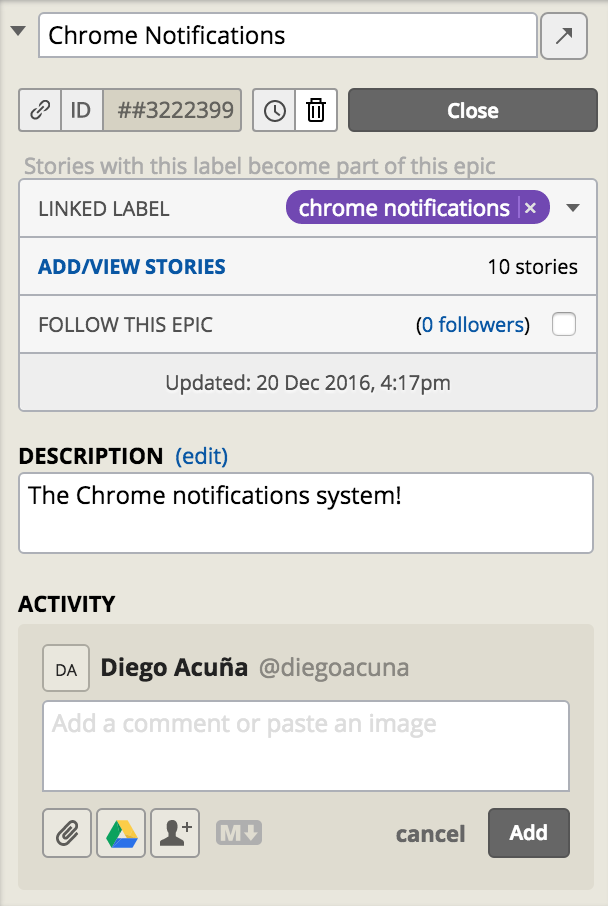
In the image above, PivotalTracker allows to click on “Add/View Stories” to have a full panel dedicated to the selected Epic. If you need to add relevant information to the epic, you should use the “Activity” section on the Epic.
It’s important to note that for every epic you should add a Release Card to the current Backlog. This card represents a marker that indicates when this epic should be launched, so it’s also important to set a release date to the release card:
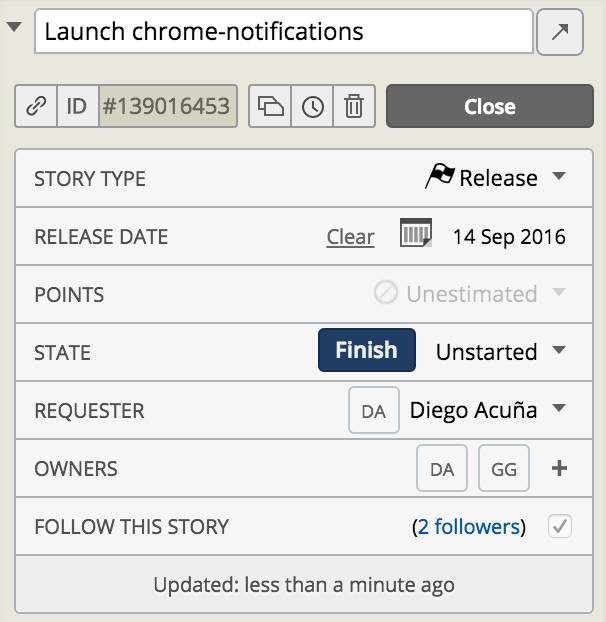
If you have an atomic story that is not related with other stories in the current backlog, then is not necessary to create an epic and a release card. The story by itself has the information of the release date for the specific feature.
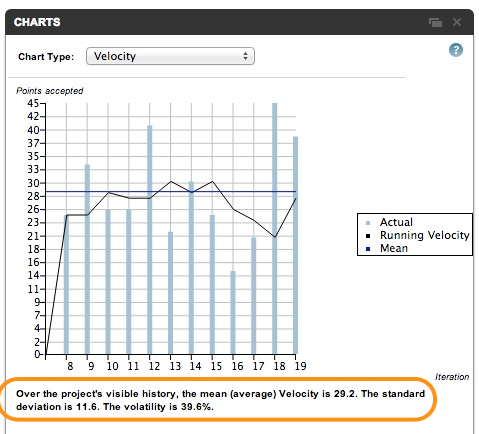
Velocity and Volatility
PivotalTracker has the ability to calculate in an automatic fashion the velocity for the current iteration of every sub-team. We recommend to follow their recommendation mainly because it’s based on the actual velocity of the previous iterations of the sub-team. Devs tend to be too optimistic in their estimations so a more ‘scientific’ approach is always welcome. For the initial iterations, it is highly probable that your are going to struggle to adapt to the suggested velocity of PivotalTracker but on next iterations the velocity will reach a more stable and representative value.
Another interesting concept in PivotalTracker is the volatility of the velocity in the team. This value represents the variation of the velocity through the iterations in the project. For example:
- 1st iteration: 12 points
- 2nd iteration: 16 points
- 3rd iteration: 5 points
The volatility for the project is:
Volatility = (Standard Deviation of Velocity * 100) / Mean of Velocity = 50.5%
This is a extremely high value. As a rule of thumbs, teams should try to have a low volatility because in general terms the work of team should be as stable as possible (in terms of productivity). A high volatility could reveal an unstable and unproductive team. PivotalTracker, gives all these metrics in a nice chart and as simple as possible:
Summary
In short:
- Backlog Planning:
- First day of the iteration every team has a meeting where they plan the current iteration
- Every feature should be added to the Icebox and they need to be as atomic as possible. If that is not possible (because of time constraints only), in no more than two days the requester/owner should split the story in more atomic stories.
- Every feature story in the backlog should be estimated without exception.
- If a feature involves more than one story, then create an Epic and associate every story of the feature using the label of the epic.
- For every Epic create a Release Card with a release date. Estimate the release date!
- You can’t have an Epic without a Release Card.
- For single stories (stories that by itself represent an entire feature) don’t use Epics and Release Cards. It’s not necessary.
- At the end of the Backlog Planning there should be no stories in the Icebox.
- During the Current Iteration:
- If you need to add more cards, do it. Don’t add new feature cards unless they allow for a more atomic representation of a feature in the current backlog. In general you should be adding only new chore/bugs cards.
- If a new feature or a not so important bug/chore arrives, add it to the Icebox.
- New bugs are solved according to priority. If it has a high priority then add it to the current backlog and solve it right away. For low priority bugs use your intuition and criteria (add them to the current backlog or to the icebox).
- As soon as a story is finished click the finish button in PivotalTracker!
- General Rules:
- Keep your boards organized. They are your day to day agenda, so if you keep boards organized your work is going to be organized too.
- Keep control of the volatility: close features as soon as they are finished. Work on one (max two) stories at the same time. Choose the right type of card (are you marking a real feature as a chore? this is going to impact the real velocity of your team!).
- Document and document again: decisions in the team tend to be forgotten through time unless they are documented. Use the Activity section on each card to document each decision regarding to that features/chore or bug.
Conclusion
Organization of a development team can be hard if you don’t follow a structured methodology. Here at AD, We favor agile practices because they give us enough flexibility in our day to day work but with enough structure to keep things organized. In practice, We use PivotalTracker as the online tool to apply our methodology and in this post our general guidelines on how to use PivotalTracker were given. If you want to keep your team organized, We recommend:
- Maintain a strong communication between team members: use any form/tool of communication (in person, Slack, Hangouts, etc.) but communicate each other on your team. Daily Meetings are a key tool for this. Communication can reduce development times by sharing knowledge and experience between devs and by avoiding misunderstandings in the team.
- Stay committed to the methodology: adapt the methodology to suit your entire team but stay committed. It’s worthless if for example only half of the team is committed and the rest is not. The entire team should be in the same direction.
- Measure, track and review: you should be constantly looking at how your team is doing. Look for key metrics such as estimated velocity, volatility, burndown and burnup charts. If you don’t track you can’t improve. Measuring and tracking allows management to adapt and take decision looking for improvement.
- Document, document and document: again, decisions are commonly forgotten if they are not documented. If some decision is important in the context of some feature or task then document that decision. Your future self will thank you.